Jsunpack [1] is a great tool to examine the structure of a PDF and extract the embedded JavaScript inside a document. Specifically, the python script “pdf.py”, which is included in Jsunpack, handles the PDF document. The “pdf.py” script displays the objects contained within a given PDF, as well as, detects embedded JavaScript and outputs the JavaScript functions to a separate file for analysis. However; “pdf.py” may not always detect the embedded JavaScript. An example of a PDF document that bypasses detection is examined later. An experimental approach is followed to figure out why jsunpack does not detect the embedded JavaScript. A solution is also presented to patch jsunpack.
2. JavaScript Detected
There are two versions of a PDF document that displays “Hello World” and pops up an alert box using JavaScript code. The first is the original version that was manually created in notepad and it displays the contents in plain text.
.PNG)
.PNG) |
| Figure 1.1 - Version 1 of the uncompressed pdf document labeled "works_original.pdf" |
 |
| Figure 1.2 - Output of pdf.py executed with version 1 of the pdf document (works_original.pdf) |
The original PDF document is labeled “works_original.pdf” since it is detected by pdf.py as containing JavaScript.
3. Javascript Not Detected
The second document is a compressed version of the “works_original.pdf” file. The second version uses FlateDecode to compress the streams. When the “works_original.pdf” is saved in Adobe Acrobat Professional 9, the application automatically compresses and converts the original version to the compressed version. Pdf.py can be used to examine the contents. We can see that the structure of the PDF has been modified. New objects are created in the document that did not exist in the “works_original.pdf”. The compressed version is labeled “notwork.pdf” since the JavaScript is not detected by pdf.py. Figure 1.3 is the output from pdf.py with the compressed version (notwork.pdf) as the input.


 |
| Figure 1.3 - Output of pdf.py executed with version 2 of the pdf document (notwork.pdf) |
A couple of interesting results can be seen from the figure above. First and most importantly, no JavaScript is detected in the compressed file. Second, all the objects are not displayed and references are included to objects that do not appear in the output. For example, object 8 has a tag “/Names” which refers to an object 13 that is not visible. To get a better idea of what is going on and what is contained in the compressed streams, the tool pdfstreamdumper [2] is used. This tool decompresses all the streams that have been encoded with filters like “FlateDecode” and presents the text in a graphical user interface.
 |
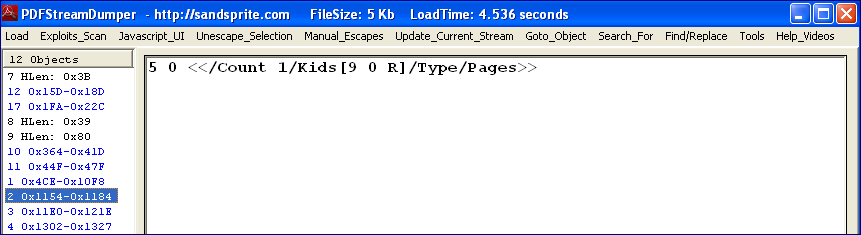
| Figure 1.4 - Objects listed by Pdfstreamdumper for the notwork.pdf |
Pdfstreamdumper provides a list of objects contained in the PDF and is displayed in Figure 1.4. The list is consistent with the output that “pdf.py” returns so where are the missing objects? If we examine each object and its contents we discover the missing objects are contained within other objects. For example, object 10 contains object 13, 14, 15 and 16.
 |
| Figure 1.5 - Contents of object 10 shown by Pdfstreamdumper for the notwork.pdf |
To understand the syntax we can refer to PDF Document Reference [3], however, it is clear after some simple analysis. As we can see from Figure 1.5 we have four objects listed consecutively. The first number is the object number and the second is the offset to the beginning of the next stream. So the first two numbers “13 0” declares the object 13 is contained first at offset 0. The next two numbers “14 22” is object 14 and the content for that object is at offset 22. The same for the next two pairs “15 49” and “16 146”. If we look back at the output of pdf.py we see the tags for object 10 and which tag allows for multiple objects.
 |
| Figure 1.6 - Snippet from the output of pdf.py for notwork.pdf |
We see that the tag “/ObjStm” allows for multiple objects to be embedded into object 10 and we can confirm by looking at the PDF Document Reference [3]. Also the tag “/N” informs us of how many objects are included inside object 10 and as we can see in Figure 1.6, and is verified by pdfstreamdumper, the number of objects inside object 10 is 4. The same process above can be followed to determine where the missing objects 5 and 6, from the pdf.py output, are located. Object 5 is embedded in Object 2. Object 6 is embedded into object 3. Figure 1.7 and Figure 1.8 show the contents of objects 2 and 6 respectively using pdfstreamdumper.
 |
| Figure 1.7 - Contents of object 2 shown in Pdfstreamdumper for the file notwork.pdf |
 |
| Figure 1.8 - Contents of object 3 shown in Pdfstreamdumper for the file notwork.pdf |
The locations of the missing objects are known and this information can be used to figure out why the pdf.py script does not detect the JavaScript in the “notwork.pdf” document. The python debugger is utilized to step through the “pdf.py” functions and determine how each object is parsed, specifically object 10. This article assumes the reader knows how to use the python debugger and does not go into detail on the debugging process.
4. Results and Solution
The results of the debugging session are the following. The python script “pdf.py” does not handle the “ObjStm” tag. Any object with a tag “/ObjStm” has a stream that is decompressed, if necessary, however, the information in the stream is not parsed by “pdf.py”. So what we can do here is inject code into pdf.py to handle the “/ObjStm” tag. Figure 1.9 is the code I wrote that detects if an object has a “/ObjStm” tag. Also it checks each object inside and determines if there exist JavaScript.
 |
| Figure 1.9 - Code created for pdf.py to address objects streams in a PDF document |
This code has also been submitted to Jsunpack’s source code and the patch request is pending review. Figure 1.9 displays the new output for “notwork.pdf” when executed with the modified “pdf.py” script which includes the code shown above.



 |
| Figure 1.10 - Output of modified pdf.py executed with the file notwork.pdf |
As we can see in Figure 1.10 the python script detects the JavaScript! The objects 13-16 and 5-6 were missing from the unmodified version. Our modification makes those objects visible in the output as well as outputs the JavaScript functions to a separate file. In the example above the JavaScript is exported to a file named “notwork.pdf.out”. Overall this solution improves upon the pdf.py script and allows it to handle objects in an object stream. More importantly it detects if JavaScript exist inside an object stream.
5. Additional Patch to Pdf.py
Another patch that has been made to the pdf.py script is in regards to the “/Names” tag. I noticed that if the “/Names” tag includes a custom name with the tag then the parsing only captures the text of the name and not the reference number. An example is shown below.
| Figure 1.11 - Snippet of the output from pdf.py for the file notwork.pdf |
For object 14 there is a “/Name” tag and the output only display the text “My Code” which is the name given to the reference to object 15. However, the reference to object 15 does not appear. After utilizing the python debugger to trace into the program, the issue is due to the parenthesis which stops the parsing function from capturing anything after the parenthesis. This is easily fixed by adding a condition to an existing “if” statement in “pdf.py”. The change is displayed in Figure 1.12.
 |
| Figure 1.12 - Code created for pdf.py to address the missing reference number for the tag "/Names" |
The tag variable is an array that contains the stream for the current object. So as well as looking for the condition “\\”, I added the condition “curtag == ‘Names’ “. This line now checks if the current tag is a “/Name” tag and if it is the parsing function will continue to collect the following characters in the tag which would include the object reference number.
| Figure 1.13 - Snippet of output from the modified pdf.py for the file notwork.pdf |
Figure 1.13 shows the new output of the modified “pdf.py” script which includes the reference as well as the text name which is given to the tag “/Names”.
6. References
[1] Jsunpack, Available at http://code.google.com/p/jsunpack-n/
[2] Pdfstreamdumper, Available at http://sandsprite.com/blogs/index.php?uid=7&pid=57
[3] Pdf Document Reference, Available at http://www.adobe.com/devnet/pdf/pdf_reference.html
How to read raw data from pdf and, in python, make app for convert to txt with preserve formatting ?
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteIt is amazing and wonderful to visit your site python Online Training
ReplyDeleteGreat Post!
ReplyDeleteThanks a lot for sharing!
I found this blog to be very useful!!
JAVA training in Bangalore